Marketing digital
Introducción al análisis causal
GADE-Uvigo 2024/25 Daniel Miles-Touya
Adaptado de presentación de Lukas Vermer
- Cambiar el color del landing page de la opción A a la B: ¿causa que más gente cliqué el anuncio?
- ¿El orden de los productos en un vending machine aumenta las ventas totales?
- ¿El gasto en publicidad aumenta las ventas?
- Simultáneamente, al mismo individuo, en el landing page con opción A y con la opción B.
- Simultáneamente, la misma vending machine con los productos ordenados de manera distinta.
- Simultáneamente, la misma empresa gastando y no gastando en publicidad.
- En este caso: el efecto del tratamiento sería simplemente la respuesta del individuo bajo opción A vs opción B.
- En este caso, sería posible obtener el efecto de un tratamiento para cada individuo.
no es posible observar simultáneamente a un mismo individuo bajo el tratamiento A y bajo el tratamiento B
- No podemos observar, simultáneamente, al mismo individuo enfrentado a los dos colores del landing page.
- No podemos observar, simultáneamente, la misma vending machine con distinto ordenamiento de productos.
- No podemos observar, simultáneamente, a una misma empresa con y sin gastos de publicidad.
Contrafactual: no podemos saber que hubiera respondido el individuo si hubiera sido asignado a la opción alternativa a la observada.
- Cada individuo sólo se observa en una única opción: opción A u opción B.
- Sólo se observa el resultado experimentado por el individuo en el tratamiento al que fue asignado.
- Por tanto, no es posible medir el efecto de la intervención para cada individuo.
- ¿Existe un efecto causal?
- ¿Cuál es el tamaño de dicho efecto?
El análisis se hace en agregado, e.g., en media, no a nivel individual.
- Algoritmo
- 1.- Realizamos un experimento
- 2.- Calculamos el efecto del esperimento: media de opción B - media opción A
- 3.- Guardamos el resultado obtenido en 2 en un container
- 4.- Repetimos de 1 a 3 R veces
- 5.- Después de R veces, calculamos la media de los resultados guardados en 3.
- Es decir, en 5 calculamos la media de los efectos obtenidos en cada experimento (que, a su vez, son una media), i.e., calculamos la media de las medias, el valor esperado del estadístico.
Esta propidad es la de insesgadez
- El valor esperado del estimador se acerca al verdadero valor de efecto a medida que aumentan las repeticiones.
- El estimador es la media de los resultados de un experimento: \(\Delta = \frac{1}{N}\sum_i^N \left[Y_i(A)-Y_i(B) \right] \).
- El valor esperado del estimador es \( E(\Delta) \), la media de su distribución (la distribución muestral).
- Para un experimento (muestra) en partícular, el resultado puede ser muy distinto al verdadero.
- Cualquier valor tiene probabilidad positiva (a no ser que el dominio esté acotado)

Cómo los histogramas de los resultados cambian cuando cambia el tamaño del efecto
En general, la hipótesis nula asume que no hay efecto causal: que el tratamiento no tiene efecto.
Los p-valores dan \(Prob(T(X) >= t(x) | H_0) \), cuando a nosotros nos gustaría saber \( Prob(H_0 | X = x) \)
Algunos ejemplos de una incorrecta interpretación- p = .05 significa que la hipótesis nula tiene un 5% de chance de ser verdadera.
- Una diferencia no-significativa (e.g. p > .05) significa que no hay diferencian entre grupos.
- p = .05 significa que los datos observados sugieren que la nula solo ocurrirá el 5% de las veces.
- p = .05 significa que si la nula se rechaza, la probabilidad del error tipo I (false positive) es 5%
[2] Goodman, Steve 2008. “A dirty dozen: twelve P-value misconceptions.” Seminars in Hematology, 45 (2008), pp. 135-140.
- Tipo I: rechazar la nula cuando es cierta.
- Tipo II: no rechazar la nula cuando es falsa.
Asumimos un pequeño efecto
La potenica es la probabilidad de rechazar la hipótesis nula cuando es falsa, i.e, cuando la alternativa es verdadera
- Cuestiones importantes: cuando se diseña un experimento hay que determinar la potenica del contraste:
- Tamaño del experimento: tamaño muestral para fijar la potencia deseada.
- El tamaño del efecto
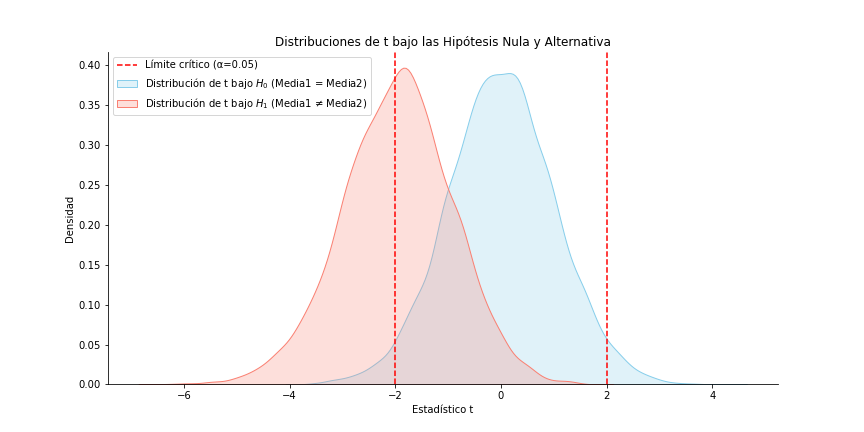
Densidad muestral del estadístico t (en R repeticiones) en la nula y en la alternativa
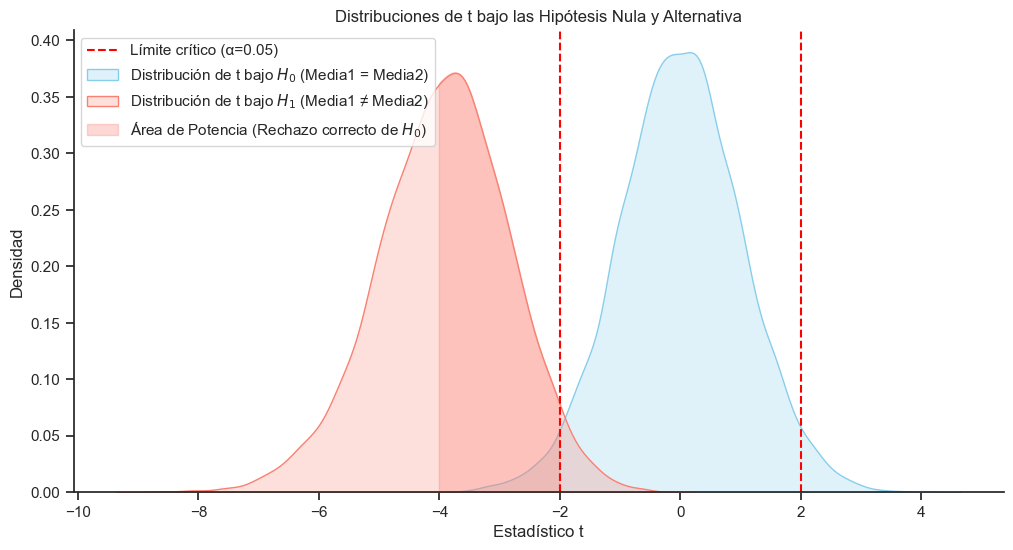
Toda el area salmon menor que -2: \(P(R H_o| H_a) \) El más oscuro señala el área que concide con t bajo H_o