A/B test
El A/B testing es una herramienta estadística que intenta evaluar si es posible generar más beneficio con un
tráfico relativente similar modificando, por ejemplo, el color de la página web.
En profano, consiste en comparar dos versiones de una misma página web o dos campañas de marketing online para comprobar cuál de las dos versiones es más eficiente. La idea es mostrar variaciones de forma aleatoria y evaluar el ouptut con métodos estadísticos.

Más concretamente, una prueba AB es un ejemplo de prueba de hipótesis estadística, un proceso mediante el cual se formula una hipótesis sobre la relación entre dos conjuntos de datos y esos conjuntos de datos se comparan entre sí para determinar si existe una relación estadísticamente significativa o no.
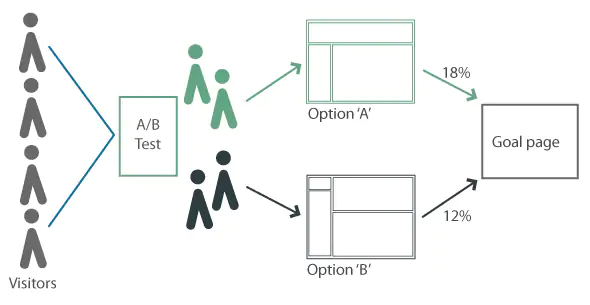
Para entender en qué consisten las pruebas A/B, consideremos dos diseños alternativos A y B. A los visitantes de un sitio web se les sirve aleatoriamente uno de los dos. A continuación, se recogen datos sobre su actividad mediante la analítica web. A partir de estos datos, se pueden aplicar pruebas estadísticas para determinar si uno de los dos diseños tiene mejor eficacia.
Podríamos mirar distintos outputs. Por ejemplo, con métricas discretas que toman valores 0 y 1 se podrían analizar:
- Click through-rate: si se muestra un anuncio a un usuario, ¿hace clic en él? Si: 1, No: 0
- Conversion rate: si se muestra un anuncio a un usuario, ¿se convierte en cliente? Si: 1, No: 0
- Bounce rate: si un usuario visita un sitio web, ¿la siguiente página visitada está en el mismo sitio web? Si: 1, No: 0
Dado que la asignación de las distintas opciones es aleatoria, en media los individuos deberían ser iguales, entre todos aquellos que se autoseleccionan para visitar la página web.
En profano, consiste en comparar dos versiones de una misma página web o dos campañas de marketing online para comprobar cuál de las dos versiones es más eficiente. La idea es mostrar variaciones de forma aleatoria y evaluar el ouptut con métodos estadísticos.
Más concretamente, una prueba AB es un ejemplo de prueba de hipótesis estadística, un proceso mediante el cual se formula una hipótesis sobre la relación entre dos conjuntos de datos y esos conjuntos de datos se comparan entre sí para determinar si existe una relación estadísticamente significativa o no.
Para entender en qué consisten las pruebas A/B, consideremos dos diseños alternativos A y B. A los visitantes de un sitio web se les sirve aleatoriamente uno de los dos. A continuación, se recogen datos sobre su actividad mediante la analítica web. A partir de estos datos, se pueden aplicar pruebas estadísticas para determinar si uno de los dos diseños tiene mejor eficacia.
Podríamos mirar distintos outputs. Por ejemplo, con métricas discretas que toman valores 0 y 1 se podrían analizar:
- Click through-rate: si se muestra un anuncio a un usuario, ¿hace clic en él? Si: 1, No: 0
- Conversion rate: si se muestra un anuncio a un usuario, ¿se convierte en cliente? Si: 1, No: 0
- Bounce rate: si un usuario visita un sitio web, ¿la siguiente página visitada está en el mismo sitio web? Si: 1, No: 0
Dado que la asignación de las distintas opciones es aleatoria, en media los individuos deberían ser iguales, entre todos aquellos que se autoseleccionan para visitar la página web.
En este tutorial vamos a utilizar datos de un experimeto AB para evaluar cuál de los dos diseños, A o B, es más eficiente en términos de conversion rates.
El experimento se desarrollo por 180 días en un e.commerce de ropa.
Estamos llevando a cabo una campaña online A por un período de tiempo. Pero queremos probar una nueva campaña B, para ver si se desempeña mejor que la anterior.
¿Cómo podemos saber cuál campaña es mejor?
Experimento: vamos a presentar la campaña A y la campaña B de forma aleatoria a los potenciales clientes -usuarios de la web-.
El output que vamos a utilizar será el conversion rate (e.g., click en carro de compras) per click en el adword.
Se va a correr el experimento por seis meses, durante el cuál obtendremos los daily clicks y conversions rate de cada campaña.
Utilizaremos estos datos para determinar qué campaña es mejor.